HDFS特性概述
优缺点
优点
-
高容错性:可以由数百或数千个服务器机器组成,每个服务器机器存储文件系统数据的一部分;数据自动保存多个副本,副本丢失后检测故障快速,自动恢复。
-
适合批处理:移动计算,而不是数据;数据的位置暴露给计算框架;数据访问高吞吐量,运行的应用程序对其数据集进行流式访问。
-
适合大数据的处理:典型文件大小为千兆以上
-
流式文件写入:一次写入,多次读取,文件一旦写入,不能修改,只能增加
-
跨异构硬件,可安装在廉价机器上
缺点
-
不适合低延迟数据访问
-
不适合小文件读取
-
不支持并发写入,只能一个线程写入,不能同时多个线程,只支持追加,不支持随机修改
架构
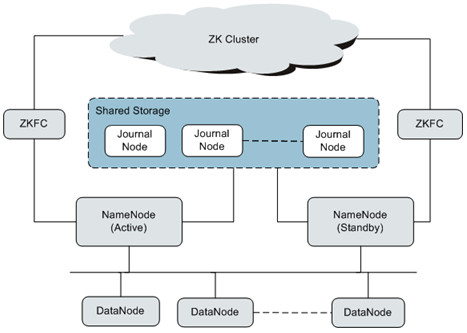
-
NameNode: 用于管理文件系统的命名空间、目录结构、元数据信息以及提供备份机制等
-
Active NameNode:管理文件系统的命名空间、维护文件系统的目录结构树以及元数据信息;记录写入的每个“数据块”与其归属文件的对应关系。
-
Standby NameNode:与Active NameNode中的数据保持同步;随时准备在Active NameNode出现异常时接管其服务。
-
-
DataNode :用于存储每个文件的“数据块”数据,并且会周期性地向NameNode报告该DataNode的数据存放情况;
-
JournalNode:HA集群下,基于QJM(Quorum Journal Manager)的HA解决方案,主备NameNode之间通过配置一组JouralNode来同步元数据信息,通常配置奇数个(2N+1个)JournalNode,且最少要运行3个JournalNode,最多容忍N个JournalNode写入失败;
-
ZKFC:是需要和NameNode一一对应的服务,即每个NameNode都需要部署ZKFC。它负责监控NameNode的状态,并及时把状态写入Zookeeper。ZKFC也有选择谁作为Active NameNode的权利;
-
ZK Cluster:ZooKeeper是一个协调服务,帮助ZKFC执行主NameNode的选举。
-
HttpFS gateway: HttpFS是个单独无状态的gateway进程,对外提供webHDFS接口,对HDFS使用FileSystem接口对接。可用于不同Hadoop版本间的数据传输,及用于访问在防火墙后的HDFS(HttpFS用作gateway)。
原理
在HDFS内部,一个文件分成一个或多个“数据块”,这些“数据块”存储在DataNode集合里,NameNode负责保存和管理所有的HDFS元数据。客户端连接到NameNode,执行文件系统的“命名空间”操作,例如打开、关闭、重命名文件和目录,同时决定“数据块”到具体DataNode节点的映射。DataNode在NameNode的指挥下进行“数据块”的创建、删除和复制。客户端连接到DataNode,执行读写数据块操作。